A Tiny Corruption-Proof Write-Ahead Log in Go
Write-Ahead Logs are boring. That’s their job.
A WAL exists to do exactly one thing: never lie. If it says a write is durable, it had better survive power loss, kernel panic, and whatever the storage stack feels like doing that day.
Unfortunately, “append bytes to a file and fsync” is not a WAL. Crashes don’t respect record boundaries, disks don’t respect your assumptions, and recovery code is where optimism goes to die.
This post walks through a small WAL in Go that’s built around a simple principle:
✨ If something looks wrong, stop immediately.
No guessing. No repair attempts. No “probably fine.”
The Record Format

Each record is self-contained and defensively structured. The layout is boring on purpose.
const (
crcSize = 4
lenSize = 4
trailerSize = 8
headerSize = crcSize + lenSize
trailerMagic = 0xDEADBEEFFEEDFACE
)On disk, a record looks like:
- CRC32 (4 bytes) – checksum of everything except itself
- Length (4 bytes) – payload size (
uint32, little-endian) - Data (N bytes) – the actual record
- Trailer (8 bytes) – a fixed magic value
- Padding (0–7 bytes) – zeroes, to keep things aligned
If this feels redundant, good. Redundancy is how storage code stays honest.
Layer 0: The Trailer (a.k.a. “Did This Even Finish?”)
The trailer is written last. Its only purpose is to prove the record fully made it to disk.
If the process crashes halfway through a write, recovery won’t see the magic value and will treat the record as nonexistent.
binary.LittleEndian.PutUint64(
buf[trailerOffset:trailerOffset+8],
trailerMagic,
)No trailer, no record. Schrödinger’s write is not allowed to collapse.
Layer 1: CRC32 (Trust, but Verify)
Once we know a record finished, we still need to know whether it’s correct.
The CRC catches:
- Bit flips
- Disk corruption
- Torn writes inside the payload
crcStored := binary.LittleEndian.Uint32(buf[0:4])
crcComputed := crc32.Checksum(buf[4:], crcTable)
if crcStored != crcComputed {
return ErrCorrupt
}If the checksum doesn’t match, recovery stops. We don’t skip the record and keep going — corruption tends to travel in packs.
Layer 2: 8-Byte Alignment (Preventing “Creative” Lengths)
Headers are small, which makes them dangerous. A torn 8-byte header can turn a reasonable length into “please allocate 4TB.”
To reduce the odds, every record is padded so the next header starts on an 8-byte boundary.
func alignUp(n int64) int64 {
return (n + 7) &^ 7
}This doesn’t make torn writes impossible, it just makes them much less exciting.
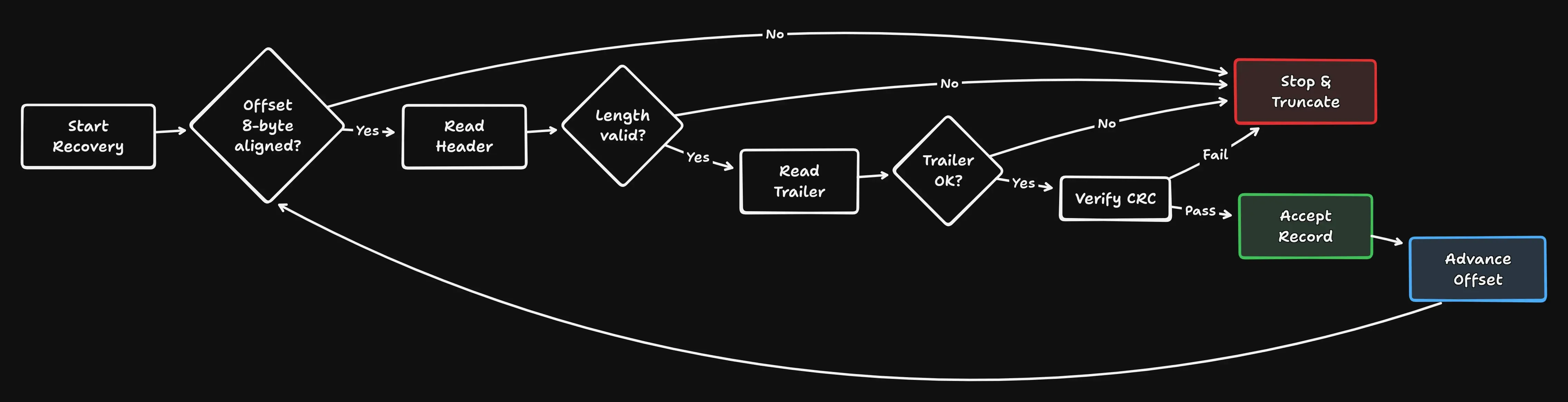
Recovery: (Always) Be Pessimistic
Recovery walks the file sequentially:
- Read header
- Validate length
- Verify trailer
- Check CRC
- Advance to the next aligned offset
The first time anything fails, recovery stops and truncates the file to the last known-good position.
No skipping. No “best effort.” No heroics.
Storage code that tries to be clever during recovery usually becomes a postmortem.
Why the Magic Number Exists
The trailer value is trailerMagic (0xDEADBEEFFEEDFACE), which is silly and very much on purpose.
It’s inspired by a real etcd bug (#6191), where a partially written record corrupted the entire log. The fix was the same idea: a hard commit marker written last.
If the marker is there, the record is real. If it’s not, it never happened.
This is the WAL equivalent of “pics or it didn’t happen.”
Design Philosophy
| Mechanism | Problem | Response |
|---|---|---|
| Trailer | Crash mid‑write | Ignore incomplete record |
| CRC32 | Corruption | Stop immediately |
| Alignment | Torn headers | Avoid nonsense lengths |
| Conservative recovery | Cascading failure | Truncate and move on |
The guiding rule is simple:
✨ It’s better to lose the last few writes than to replay a lie.
Databases can recover from missing data. They don’t recover from corrupted truths.
My thoughts, references and source-code
Inspiration for this blog: UnisonDB blog post on corruption-proof WALs
This WAL design was inspired by UnisonDB’s post on building a corruption-proof write-ahead log in Go. I followed a similar philosophy of ‘stop on corruption’ and layer-based safety checks.
While UnisonDB focuses on a high-performance WAL for production use, this post explores a minimal, easy-to-understand version suitable for learning or small projects.
This WAL is intentionally simple and safe. It is not optimized for speed—fsyncs, CRC32 checks, and alignment add overhead—but correctness and detectability of corruption is the priority.
You can find the full-implementation of my code here.
This is a toy project and that’s why it isn’t fast, clever, or novel. It’s intentionally dull.
But it has one nice property: when something goes wrong, it fails loudly and early, instead of quietly poisoning your state.
In storage systems, boring is a feature and excitement is usually a bug 🐛.